Композиция для монады IO
Пока мы не написали ещё ни одной программы, которой можно было бы пользоваться вне интерпретатора. Предполагается, что программа как-то взаимодействует с пользователем (ожидает ввода с клавиатуры) и изменяет состояние компьютера (выводит сообщения на экран, записывает данные в файлы). Но пока что мы не знаем как взаимодействовать с окружающим миром.
Самое время узнать! Сначала мы посмотрим какие проблемы связаны с реализацией взаимодействия с пользователем. Как эти проблемы решаются в Haskell. Потом мы научимся решать несколько типичных задач, связанных с вводом/выводом.
Когда мы определяем новые функции или константы мы лишь даём новые имена комбинациям значений. В этом смысле у нас ничего не изменяется. По-другому это называется функциональной чистотой (referential transparency). Это свойство говорит о том, что мы свободно можем заменить в тексте программы любой синоним на его определение и это никак не скажется на результате.
Функция является чистой, если её выход зависит только от её входов. В любой момент выполнения программы для одних и тех же входов будет один и тот же выход. Это свойство очень ценно. Оно облегчает понимание поведения функции. Оно говорит о том, что функция может зависеть от других функций только явно. Если мы видим, что другая функция используется в данной функции, то она используется в этой функции. У нас нет таинственных глобальных переменных, в которые мы можем записывать данные из одной функции и читать их с помощью другой. Мы вообще не можем ничего записывать и ничего читать. Мы не можем изменять состояния, мы можем лишь давать новые имена или строить новые выражения из уже существующих.
Но в этот статичный мир описаний не вписывается взаимодействие с пользователем. Предположим, что мы хотим написать такую программу: мы набираем на клавиатуре имя файла, нажимаем Enter и программа показывает на экране содержимое этого файла, затем мы набираем текст, нажимаем Enter и текст дописывается в конец файла, файл сохраняется. Это описание предполагает упорядоченность действий. Мы не можем сначала сохранить текст, затем прочитать обновления. Тогда текст останется прежним.
Ещё один пример. Предположим у нас есть функция getChar, которая читает букву с клавиатуры. И функция print, которая выводит строку на экран И посмотрим на такое выражение:
let c = getChar in print $ c : c : []
О чём говорит это выражение? Возможно, прочитай с клавиатуры букву и выведи её на экран дважды. Но возможен и другой вариант, если в нашем языке все определения это синонимы мы можем записать это выражение так:
print $ getChar : getChar : []
Это выражение уже говорит о том, что читать с клавиатуры необходимо дважды! А ведь мы сделали обычное преобразование, заменили вхождения синонима на его определение, но смысл изменился. Взаимодействие с пользователем нарушает чистоту функций, нечистые функции называются функциями с побочными эффектами.
Как быть? Можно ли внести в мир описаний порядок выполнения, сохранив преимущества функциональной чистоты? Долгое время этот вопрос был очень трудным для чистых функциональных языков. Как можно пользоваться языком, который не позволяет сделать такие базовые вещи как ввод/вывод?
Где-то мы уже встречались с такой проблемой. Когда мы говорили о типе ST и обновлении значений. Там тоже были проблемы порядка вычислений, нам удалось преодолеть их с помощью скрытой передачи фиктивного состояния. Тогда наши обновления были чистыми, мы могли безболезненно скрыть их от пользователя. Теперь всё гораздо труднее. Нам всё-таки хочется взаимодействовать с внешним миром. Для обозначения внешнего мира мы определим специальный тип и назовём его RealWorld:
module IO(
IO
) where
data RealWorld = RealWorld
newtype IO a = IO (ST RealWorld a)
instance Functor IO where ...
instance Applicative IO where ...
instance Monad IO where ...
Тип IO (от англ. input-output или ввод-вывод) обозначает взаимодействие с внешним миром. Внешний мир словно является состоянием наших вычислений. Экземпляры классов композиции специальных функций такие же как и для ST (а следовательно и для State). Но при этом, поскольку мы конкретизировали первый параметр типа ST, мы уже не сможем воспользоваться функцией runST.
Тип RealWorld определён в модуле Control.Monad.ST, там же можно найти и функцию:
stToIO :: ST RealWorld a -> IO a
Интересно, что класс Monad был придуман как раз для решения проблемы ввода-вывода. Классы типов изначально задумывались для решения проблемы определения арифметических операций на разных числах и функции сравнения на равенство для разных типов, мало кто тогда догадывался, что классы типов сыграют такую роль, станут основополагающей особенностью языка.
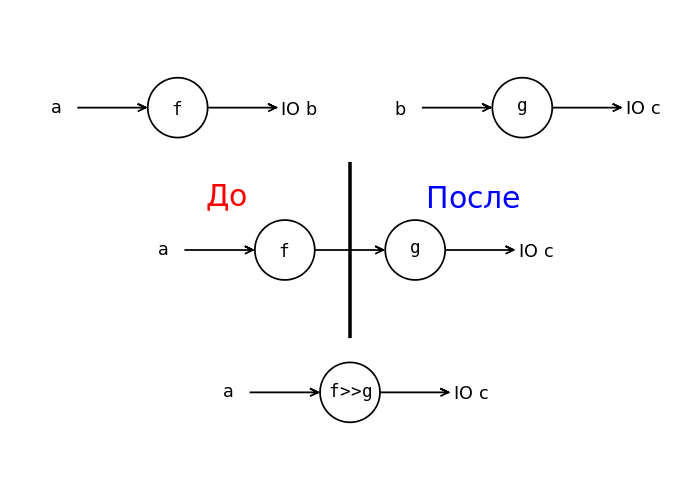
Композиция для монады IO
Это рисунок для класса Kleisli. Здесь под >> понимается композиция, как мы её определяли в главе 6, а не метод класса Monad, вспомним определение:
class Kleisli m where
idK :: a -> m a
(>>) :: (a -> m b) -> (b -> m c) -> (a -> m c)
Композиция специальных функций типа a -> IO b вносит порядок вычисления. Считается, что сначала будет вычислена функция слева от композиции, а затем функция справа от композиции. Это происходит за счёт скрытой передачи фиктивного состояния. Теперь перейдём к классу Monad. Там композиция заменяется на применение или операция связывания:
ma >>= mf
Для типа IO эта запись говорит о том, что сначала будет выполнено выражение ma и результат будет подставлен в выражение mf и только затем будет выполнено mf. Оператор связывания для специальных функций вида:
a -> IO b
раскалывает наш статический мир на “до” и “после”. Однажды попав в сети IO, мы не можем из них выбраться, поскольку теперь у нас нет функции runST. Но это не так страшно. Тип IO дробит наш статический мир на кадры. Но мы спокойно можем создавать статические чистые функции и поднимать их в мир IO лишь там где это действительно нужно.
Рассмотрим такой пример, программа читает с клавиатуры начальное значение, затем загружает файл настроек. Потом запускается, какая-то сложная функция и в самом конце мы выводим результат на экран.
Схематично мы можем записать эту программу так:
program = liftA2 algorithm readInit (readConfig "file") >>= print -- функции с побочными эффектами readInit :: IO Int readConfig :: String -> IO Config print :: Show a => a -> IO () -- большая и сложная, но !чистая! функция algorithm :: Int -> Config -> Result
Функция readInit читает начальное значение, функция readConfig читает из файла настройки, функция print выводит значение на экран, если это значение можно преобразовать в строку. Функция algorithm это большая функция, которая вычисляет какие-то данные. Фактически наше программа это и есть функция algorithm. В этой схеме мы добавили взаимодействие с пользователем лишь в одном месте, вся функция algorithm построена по правилам мира описаний. Так мы внесли порядок выполнения в программу, сохранив возможность определения чистых функций.
Если у нас будет ещё один “кадр”, ещё одно действие, например как только функция algorithm закончила вычисления ей нужны дополнительные данные от пользователя, на основе которых мы сможем продолжить вычисления с помощью какой-нибудь другой функции. Тогда наша программа примет вид:
program =
liftA2 algorithm2 readInit
(liftA2 algorithm1 readInit (readConfig "file"))
>>= print
-- функции с побочными эффектами
readInit :: IO Int
readConfig :: String -> IO Config
print :: Show a => a -> IO ()
-- большие и сложные, но !чистые! функции
algorithm1 :: Int -> Config -> Result1
algorithm2 :: Int -> Result1 -> Result2
Теперь у нас два кадра, программа выполняется в два этапа. Каждый из них разделён участками взаимодействия с пользователем. Но тип IO присутствует лишь в первых шести строчках, остальные два миллиона строк написаны в мире описаний, исключительно чистыми функциями, которые поднимаются в мир специальных функций с помощью функций liftA2 и стыкуются с помощью операции связывания >>=.
Попробуем тип IO в интерпретаторе. Мы будем пользоваться двумя стандартными функциями getChar и print
-- читает символ с клавиатуры getChar :: IO Char -- выводит значение на экран print :: IO ()
Функция print возвращает значение единичного типа, завёрнутое в тип IO, поскольку нас интересует не само значение а побочный эффект, который выполняет эта функция, в данном случае это вывод на экран.
Закодируем два примера из первого раздела. В первом мы читаем один символ и печатаем его дважды:
Prelude> :m Control.Applicative Prelude Control.Applicative> let res = (\c -> c:c:[]) <$> getChar >>= print Prelude Control.Applicative> res q"qq"
Мы сначала вызываем функцию getChar удваиваем результат функцией \c -> c:c:[] и затем выводим на экран.
Во втором примере мы дважды запрашиваем символ с клавиатуры а затем печатаем их:
Prelude Control.Applicative> let res = liftA2 (\a b -> a:b:[]) getChar getChar >>= print Prelude Control.Applicative> res qw"qw"
Мы уже умеем читать с клавиатуры и выводить значения на экран. Давайте научимся писать самостоятельные программы. Программа обозначается специальным именем:
main :: IO ()
Если модуль называется Main или в нём нет директивы module ... where и в модуле есть функция main :: IO (), то после компиляции будет сделан исполняемый файл. Его можно запускать независимо от ghci. Просто нажимаем дважды мышкой или вызываем из командной строки.
Напишем программу Hello world. Единственное, что она делает это выводит на экран приветствие:
main :: IO () main = print "Hello World!"
Теперь сохраним эти строчки в файле Hello.hs, перейдём в директорию файла и скомпилируем файл:
ghc --make Hello
Появились объектный и интерфейсный файлы, а также появился третий бинарный файл. Это либо Hello без расширения (в Linux) или Hello.exe (в Windows). Запустим этот файл:
$ ./Hello "Hello World!"
Получилось! Это наша первая программа. Теперь напишем программу, которая принимает три символа с клавиатуры и выводит их в обратном порядке:
import Control.Applicative f :: Char -> Char -> Char -> String f a b c = reverse $ [a,b,c] main :: IO () main = print =<< f <$> getChar <*> getChar <*> getChar
Сохраним в файле ReverseIO.hs и скомпилируем:
ghc --make ReverseIO -o rev3
Дополнительным флагом -o мы попросили компилятор чтобы он сохранил исполняемый файл под именем rev3. Теперь запустим в командной строке:
$ ./rev3 qwe "ewq"
Набираем три символа и нажимаем ввод. И программа переворачивает ответ. Обратите внимание на то, что с помощью print мы выводим не просто строку на экран, а строку как значение. Поэтому добавляются двойные кавычки. Для того чтобы выводить строку существует функция putStr. Заменим print на putStr, перекомпилируем и посмотрим что получится:
$ ghc --make ReverseIOstr -o rev3str [1 of 1] Compiling Main ( ReverseIOstr.hs, ReverseIOstr.o ) Linking rev3str ... $ ./rev3str 123 321$
Видно, что после вывода не произошёл перенос каретки, терминал приглашает нас к вводу команды сразу за ответом, если перенос нужен, можно воспользоваться функцией putStrLn. Обратите внимание на то, что кроме бинарного файла появились ещё два файла с расширениями .hi и .o. Первый файл называется интерфейсным он описывает какие в модуле определения, а второй файл называется объектным. Он содержит скомпилированный код модуля.
Стоит отметить команду runhaskell. Она запускает программу без создания дополнительных файлов. Но в этом случае выполнение программы будет происходить медленнее.
Нам уже встретилось несколько функций вывода на экран. Это функции: print (вывод значения из экземпляра класса Show), putStr (вывод строки) и putStrLn (вывод строки с переносом). Каждый раз когда мы набираем какое-нибудь выражение в строке интерпретатора и нажимаем Enter, интерпретатор применяет к выражению функцию print и мы видим его на экране.
Из простейших функций вывода на экран осталось не рассмотренной лишь функция putChar, но я думаю вы без труда догадаетесь по типу и имени чем она занимается:
putChar :: Char -> IO ()
Функции вывода на экран также можно вызывать в интерпретаторе:
Prelude> putStr "Hello" >> putChar ' ' >> putStrLn "World!" Hello World!
Обратите внимание на применение постоянной функции для монад >>. В этом выражении нас интересует не результат, а те побочные эффекты, которые выполняются при композиции специальных функций. Также мы пользовались функцией >> в сочетании с монадой Writer для накопления результата.
Мы уже умеем принимать от пользователя буквы. Это делается функцией getChar. Функцией getLine мы можем прочитать целую строчку. Строка читается до тех пор пока мы не нажмём Enter.
Prelude> fmap reverse $ getLine Hello-hello! "!olleh-olleH"
Есть ещё одна функция для чтения строк, она называется getContents. Основное отличие от getLine заключается в том, что содержание не читается сразу, а откладывается на потом, когда содержание действительно понадобится. Это ленивый ввод. Для задачи чтения символов с терминала эта функция может показаться странной. Но часто в символы вводятся не вручную, а передаются из другого файла. Например, если мы направим на ввод данные из какого-нибудь большого-большого файла, файл не будет читаться сразу, и память не будет заполнена не нужным пока содержанием. Вместо этого программа отложит считывание на потом и будет заниматься им лишь тогда, когда оно понадобится в вычислениях. Это может существенно снизить расход памяти. Мы читаем файл в 2Гб моментально (мы делаем вид, что читаем его). А на самом деле сохраняем себе задачу на будущее: читать ввод, когда придёт пора.
Для чтения и записи файлов есть три простые функции:
type FilePath = String -- чтение файла readFile :: FilePath -> IO String -- запись строки в файл writeFile :: FilePath -> String -> IO () -- добавление строки в конеци файла appendFile :: FilePath -> String -> IO ()
Напишем программу, которая сначала запрашивает путь к файлу. Затем показывает его содержание. Затем запрашивает ввод строки из терминала. А после этого добавляет текст в конец файла.
main = msg1 >> getLine >>= read >>= append
where read file = readFile file >>= putStrLn >> return file
append file = msg2 >> getLine >>= appendFile file
msg1 = putStr "input file: "
msg2 = putStr "input text: "
В самом левом вызове getLine мы читаем имя файла, затем оно используется в локальной функции read. Там мы читаем содержание файла (readLine), выводим его на экран (putStrLn), и в самом конце мы возвращаем из функции имя файла. Оно нам понадобится в следующей части программы, в которой мы будем читать новые записи и добавлять их в файл. Новая запись читается функцией getLine в локальной функции append.
Сохраним в модуле File.hs и посмотрим, что у нас получилось. Перед этим создадим в текущей директории тестовый пустой файл под именем test. В него мы будем добавлять новые записи.
*Prelude> :l File [1 of 1] Compiling File ( File.hs, interpreted ) Ok, modules loaded: File. *File> main input file: test input text: Hello! *File> main input file: test Hello! input text: Hi) *File> main input file: test Hello!Hi)
В самом начале наш файл пуст, поэтому сначала мы видим пустую строчку вместо содержания, но потом мы начинаем добавлять в него новые записи.
С чтением файлов связана одна тонкость. Функция readFile читает содержимое файла в ленивом стиле. Подробнее о ленивой стратегии вычислений мы поговорим в следующей главе. По ка отметим, что readFile не читает следующую порцию файла до тех пор пока она не понадобится в программе. Иногда это очень удобно. Например мы можем читать содержание очень большого файла и составлять какую-нибудь статистику на основе прочитанного текста. При этом в памяти будет храниться лишь малая часть файла. Но иногда это свойство мешает. Рассмотрим такую задачу: перевернуть текст в файле под именем "test". Мы должны сначала считать текст из файла, затем перевернуть его и в конце записать в тот же файл. Мы могли бы написать эту программу так:
module Main where main :: IO () main = inFile reverse "test" inFile :: (String -> String) -> FilePath -> IO () inFile fun file = writeFile file . fun =<< readFile file
Функция inFile обновляет текст файла с помощью некоторого преобразование. Но если мы запустим эту программу:
*Main> main *** Exception: test: openFile: resource busy (file is locked)
Мы получили ошибку. Мы пытаемся писать в файл, который уже занят для чтения. Дело в том, что функция readFile заняла файл, за счёт чтения по кусочкам. Для решения этой проблемы необходимо воспользоваться энергичной версией функции readFile, она будет читать файл целиком. Эта функция живёт в модуле System.IO.Strict:
import qualified System.IO.Strict as StrictIO inFile :: (String -> String) -> FilePath -> IO () inFile fun file = writeFile file . fun =<< StrictIO.readFile file
Функция main осталась прежней. Теперь наша программа спокойно переворачивает текст файла.
Пока программы, которые мы создавали просили пользователя ввести данные вручную при выполнении программы, они работали в интерактивном режиме, но чаще всего программы принимают какие-нибудь начальные данные, установки или флаги. Читать начальные данные можно с помощью функций из модуля System.Environment.
Узнать, что передаётся в программу можно функцией getArgs :: IO [String]. Она возвращает список строк. Это те строки, что мы написали за именем программы через пробел при вызове в терминале. Напишем простую программу, которая распечатывает свои аргументы по порядку, в виде пронумерованного списка.
module Main where
import System.Environment
main = getArgs >>= mapM_ putStrLn . zipWith f [1 .. ]
where f n a = show n ++ ": " ++ a
В локальной функции f мы присоединяем к строке номер через двоеточие. Функцией mapM_ мы пробегаем по списку строк, отображая их с помощью функции putStrLn. Обратите внимание на краткость программы, с помощью функции композиции мы легко составили функцию, которая приписывает к аргументам числа, а затем выводит их на экран.
Скомпилируем программу в интерпретаторе и вызовем её.
*Main> :! ghc --make Args [1 of 1] Compiling Main ( Args.hs, Args.o ) Linking Args ... *Main> :! ./Args hey hey hey 23 54 "qwe qwe qwe" fin 1: hey 2: hey 3: hey 4: 23 5: 54 6: qwe qwe qwe 7: fin
Если мы хотим, чтобы аргумент-строка содержал пробелы мы заключаем его в двойные кавычки.
С помощью функции getProgName можно узнать имя программы. Создадим программу, которая здоровается при вызове. И отвечает в зависимости от настроения программы. Настроение задаётся аргументом программы.
module Main where
import Control.Applicative
import System.Environment
main = putStrLn =<< reply <$> getProgName <*> getArgs
reply :: String -> [String] -> String
reply name (x:_) = hi name ++ case x of
"happy" -> "What a lovely day. What's up?"
"sad" -> "Ooohh. Have you got some news for me?"
"neutral" -> "How are you?"
reply name _ = reply name ["neutral"]
hi :: String -> String
hi name = "Hi! My name is " ++ name ++ ".\n"
В функции reply мы составляем реплику программы. Она зависит от имени программы и поступающих на вход аргументов. Посмотрим, что у нас получилось:
*Main> :! ghc --make HowAreYou.hs -o ninja [1 of 1] Compiling Main ( HowAreYou.hs, HowAreYou.o ) Linking ninja ... *Main> :! ./ninja happy Hi! My name is ninja. What a lovely day. What's up? *Main> :! ./ninja sad Hi! My name is ninja. Ooohh. Have you got some news for me?
Мы можем вызвать любую программу из нашей программы. Это делается с помощью функции system, которая живёт в модуле System.
system :: String -> IO ExitCode
Она принимает строку и запускает её в терминале. Так же как мы делали это с помощью приставки :! в интерпретаторе. Значение типа ExitCode говорит о результате выполнения строки. Он может быть успешным, тогда функция вернёт ExitSuccess и закончиться ошибкой, тогда мы сможем узнать код ошибки по значению ExitFailure Int.
Функции для создания случайных значений определены в модуле System.Random. Модуль System.Random входит в библиотеку random. Если в вашей поставке ghc его не оказалось, вы можете установить его вручную через интернет, набрав в командной строке cabal install random. Сначала давайте разберёмся как генерируются случайные числа. Стандартные случайные числа очень похожи на те, что были у нас, когда мы рассматривали примеры специальных функций. У нас есть генератор случайных чисел типа g и с помощью функции next мы можем получить обновлённый генератор и случайное целое число:
next :: g -> (Int, g)
Не правда ли этот тип очень похож на тип результата функций с состоянием. В качестве состояния теперь выступает генератор случайных чисел g. Это поведение описывается классом RandomGen:
class RandomGen g where
next :: g -> (Int, g)
split :: g -> (g, g)
geтRange :: g -> (Int, Int)
Функция next обновляет генератор и возвращает случайное значение типа Int. Функция split раскалывает один генератор на два. Функция genRange возвращает диапазон значений генерируемых случайных чисел. Первое значение в паре результата genRange должно быть всегда меньше второго. Для этого класса определён один экземпляр, это тип StdGen. Мы можем создать первый генератор по целому числу с помощью функции mkStdGen:
mkStdGen :: Int -> StdGen
Давайте посмотрим как это происходит в интерпретаторе:
Prelude> :m System.Random Prelude System.Random> let g0 = mkStdGen 0 Prelude System.Random> let (n0, g1) = next g0 Prelude System.Random> let (n1, g2) = next g1 Prelude System.Random> n0 2147482884 Prelude System.Random> n1 2092764894
Мы создали первый генератор, а затем начали получать новые. Для того, чтобы получать новые случайные числа, нам придётся таскать везде за собой генератор случайных чисел. Мы можем обернуть его в функцию с состоянием и пользоваться методами классов Functor, Applicative и Monad. Обновление генератора будет происходить за ширмой, во время применения функций. Но у нас есть и другой путь.
Вместо монады State мы можем воспользоваться монадой IO. Если нам лень определять генератор случайных чисел, мы можем попросить компьютер определить его за нас. В этом случае мы взаимодействуем с компьютером, мы запрашиваем глобальное для системы случайное значение, поэтому возвращаемое значение будет завёрнуто в тип IO. Для этого определены функции:
getStdGen :: IO StdGen newStdGen :: IO StdGen
Функция getStdGen запрашивает глобальный для системы генератор случайных чисел. Функция newStdGen не только запрашивает генератор, но также и обновляет его. Мы пользуемся этими функциями так же как и mkStdGen, только теперь мы спрашиваем первый аргумент у компьютера, а не передаём его вручную. Также есть ещё одна полезная функция:
getStdRandom :: (StdGen -> (a, StdGen)) -> IO a
Посмотрим, что получится, если передать в неё функцию next:
Prelude System.Random> getStdRandom next 1386438055 Prelude System.Random> getStdRandom next 961860614
И не надо обновлять никаких генераторов. Но вместо одного неудобства мы получили другое. Теперь значение завёрнуто в оболочку IO.
Генератор StdGen делает случайные числа из диапазона всех целых чисел. Что если мы хотим получить только числа из некоторого интервала? И как получить случайные значения других типов? Для этого существует класс Random. Он является удобной надстройкой над классом RandomGen. Посмотрим на его основные методы:
class Random a where
randomR :: RandomGen g => (a, a) -> g -> (a, g)
random :: RandomGen g => g -> (a, g)
Метод randomR принимает диапазон значений, генератор случайных чисел и возвращает случайное число из указанного диапазона и обновлённый генератор. Метод random является синонимом метода next из класса RandomGen, только теперь мы можем получать не только целые числа.
Есть и дополнительные методы. Есть методы, которые позволяют генерировать список всех возможных случайных значений для данного генератора:
randomRs :: RandomGen g => (a, a) -> g -> [a]
randoms :: RandomGen g => g -> [a]
За счёт лени мы будем получать новые значения по мере необходимости.
randomRIO :: (a, a) -> IO a
randomIO :: IO a
Эти функции выполняют тоже, что и основные функции класса, но им не нужен генератор случайных чисел, они создают его с помощью функции getStdRandom. Экземпляры Random определены для Bool, Char, Double, Float, Int и Integer. Например так мы можем подбросить кости десять раз:
Prelude System.Random> fmap (take 10 . randomRs (1, 6)) getStdGen [5,6,5,5,6,4,6,4,4,4] Prelude System.Random> fmap (take 10 . randomRs (1, 6)) getStdGen [5,6,5,5,6,4,6,4,4,4]
Обратите внимание на то, что функция getStdGen не обновляет генератор случайных чисел. Мы запрашиваем глобальное состояние. Поэтому, дважды подбросив кубик, мы получили одни и те же результаты. Генератор будет обновляться, если воспользоваться функцией newStdGen:
Prelude System.Random> fmap (take 10 . randomRs (1, 6)) newStdGen [1,1,5,6,5,2,5,5,5,3] Prelude System.Random> fmap (take 10 . randomRs (1, 6)) newStdGen [5,4,6,5,5,5,1,5,5,2]
Создадим случайные слова из пяти букв:
Prelude System.Random> fmap (take 5 . randomRs ('a', 'z')) newStdGen
"maclg"
Prelude System.Random> fmap (take 5 . randomRs ('a', 'z')) newStdGen
"nfjoa"
Напишем небольшую программу, которая будет выводить на экран в случайном порядке цитаты. Цитаты хранятся в виде списка пар (автор, высказывание). Сначала мы генерируем случайное число в диапазоне длины списка, затем выбираем цитату под этим номером и выводим её на экран.
module Main where
import Control.Applicative
import System.Random
main =
format . (quotes !! ) <$> randomRIO (0, length quotes - 1)
>>= putStrLn
format (a, b) = b ++ space ++ a ++ space
where space = "\n\n"
quotes = [
("Бьёрн Страуструп",
"Есть лишь два вида языков программирования: те, \
\ на которые вечно жалуются, и те, которые никогда \
\ не используются."),
("Мохатма Ганди", "Ты должен быть теми изменениями, которые\
\ ты хочешь видеть вокруг."),
("Сократ", "Я знаю лишь то, что ничего не знаю."),
("Китайская народная мудрость", "Сохранив спокойствие в минуту\
\ гнева, вы можете избежать сотни дней сожалений"),
("Жан Батист Мольер", "Медленно растущие деревья приносят лучшие плоды"),
("Антуан де Сент-Экзюпери", "Жить это значит медленно рождаться"),
("Альберт Эйнштейн", "Фантазия важнее знания."),
("Тони Хоар", "Внутри любой большой программы всегда есть\
\ маленькая, что рвётся на свободу"),
("Пифагор", "Не гоняйся за счастьем, оно всегда находится в тебе самом"),
("Лао Цзы", "Путешествие в тысячу ли начинается с одного шага")]
Функция format приводит цитату к виду приятному для чтения. Попробуем программу в интерпретаторе:
Prelude> :! ghc --make Quote -o hi [1 of 1] Compiling Main ( Quote.hs, Quote.o ) Linking hi ... Prelude> :! ./hi Путешествие в тысячу ли начинается с одного шага Лао Цзы Prelude> :! ./hi Не гоняйся за счастьем, оно всегда находится в тебе самом Пифагор
Мы уже знаем несколько типов, с помощью которых функции могут сказать, что что-то случилось не так. Это типы Maybe и Either. Если функции не удалось вычислить значение она возвращает специальное значение Nothing или Left reason, по которому следующая функция может опознать ошибку и предпринять какие-нибудь действия. Так обрабатываются ошибки в чистых функциях. В этом разделе мы узнаем о том, как обрабатываются ошибки, которые происходят при взаимодействии с внешним миром, ошибки, которые происходят внутри типа IO.
Ошибки функций с побочными эффектами обрабатываются с помощью специальной функции catch, она определена в Prelude:
catch :: IO a -> (IOError -> IO a) -> IO a
Эта функция принимает значение, которое содержит побочные эффекты и функцию, которая обрабатывает исключительные ситуации. К примеру если мы попытаемся прочитать данные из файла, к которому у нас нет доступа, произойдёт ошибка. Мы можем не дать программе упасть и обработать ошибку с помощью функции catch.
Например программа, в которой мы дописывали данные в файл, упадёт, если мы передадим не существующий файл. Но мы можем исправить это поведение с помощью функции catch. Мы можем перезапускать программу, если произошла ошибка:
module FileSafe where
import Control.Applicative
import Control.Monad
main = try `catch` const main
try = msg1 >> getLine >>= read >>= append
where read file = readFile file >>= putStrLn >> return file
append file = msg2 >> getLine >>= appendFile file
msg1 = putStr "input file: "
msg2 = putStr "input text: "
Часто функции двух аргументов называют так, чтобы при инфиксной форме записи получалась фраза из английского языка. Так если мы запишем catch в инфиксной форме получится очень наглядное выражение. Функция обработки ошибок реагирует на любую ошибку перезапуском программы. Попробуем взломать программу:
*FileSafe> main input file: fsldfksld input file: sd;fls;dfl;vll; d;fld;f input file: dflks;ldkf ldkfldkfld input file: lsdkfksdlf ksdkflsdfkls;dfk input file: bfk input file: test Hello!Hi) input text: HowHow
Функция будет запрашивать файл до тех пор, пока мы не введём корректное значение. Мы можем добавить сообщение об ошибке, немного изменив функцию обработки:
main = try `catch` const (msg >> main)
where msg = putStrLn "Wrong filename, try again."
А что делать если нам хочется различать ошибки по типу и предпринимать различные действия в зависимости от типа ошибки? Ошибки распознаются с помощью специальных предикатов, которые определены в модуле System.IO.Error. Рассмотрим некоторые из них.
Например с помощью с помощью предиката isDoesNotExistErrorType мы можем опознать ошибки, которые случились из-за того, что один из аргументов функции не существует. С помощью предиката isPermissionErrorType мы можем узнать, что ошибка произошла из-за того, что мы пытались получить доступ к данным, на которые у нас нет прав. Мы можем, немного изменив функцию-обработчик исключений, выводить более информативные сообщения об ошибках перед перезапуском:
main = try `catch` handler
handler :: IOError -> IO ()
handler = ( >> main) . putStrLn . msg2 . msg1
msg1 e
| isDoesNotExistErrorType e = "File does not exist. "
| isPermissionErrorType e = "Access denied. "
| otherwise = ""
msg2 = (++ "Try again.")
В модуле System.IO.Error вы можете найти ещё много разных предикатов.
Обмен данными, чтение и запись происходят с помощью потоков. Каждый поток имеет дескриптор (handle), через него мы можем общаться с потоком, например считывать данные или записывать. Функции для работы с потоками данных определены в модуле System.IO.
В любой момент в системе открыты три стандартных потока:
stdin – стандартный ввод
stdout – стандартный вывод
stderr – поток ошибок и отладочных сообщений
Например когда мы выводим строку на экран, на самом деле мы записываем строку в поток stdout. А когда мы читаем символ с клавиатуры, мы считываем его из потока stdin.
Файлы также являются потоками. При открытии файлу присваивается дескриптор через который, мы можем обмениваться данными. Файл может быть открыт для чтения, записи, дополнения (записи в конец файла) или чтения и записи. Файл открывается функцией:
openFile :: FilePath -> IOMode -> IO Handle
Функция принимает путь к файлу и режим работы с файлом и возвращает дескриптор. Режим может принимать одно из значений:
ReadMode – чтение
WriteMode – запись
AppendMode – добавление (запись в конец файла)
ReadWriteMode – чтение и запись
Открыв дескриптор, мы можем начать обмениваться данными. Для этого определены функции аналогичные тем, что мы уже рассмотрели. Функции для записи данных:
-- запись символа hPutChar :: Handle -> Char -> IO () -- запись строки hPutStr :: Handle -> String -> IO () -- запись строки с переносом каретки hPutStrLn :: Handle -> String -> IO () -- запись значения hPrint :: Show a => Handle -> a -> IO ()
Все функции принимают первым аргументом дескриптор потока. Дескриптор должен позволять записывать данные. Например для дескриптора, открытого в режиме ReadMode, выполнение этих функций приведёт к ошибке.
Из потоков также можно читать данные. Эти функции похожи на те, что мы уже рассмотрели:
-- чтение одного символа hGetChar :: Handle -> IO Char -- чтение строки hGetLine :: Handle -> IO String -- ленивое чтение строки hGetContents :: Handle -> IO String
Как только, мы закончим работу с файлом, его необходимо закрыть. Нам нужно освободить дескриптор. Сделать это можно функцией hClose:
hClose :: Handle -> IO ()
Стандартные функции ввода/вывода, которые мы рассмотрели ранее определены через функции работы с дескрипторами. Например так мы выводим строку на экран:
putStr :: String -> IO () putStr s = hPutStr stdout s
А так читаем строку с клавиатуры:
getLine :: IO String getLine = hGetLine stdin
В этих функциях используются дескрипторы стандартных потоков данных stdin и stdout. Отметим функцию withFile:
withFile :: FilePath -> IOMode -> (Handle -> IO r) -> IO r
Она открывает файл в заданном режиме выполняет функцию на его дескрипторе и и закрывает файл. Например через эту функцию определены функции readFile и appendFile:
appendFile :: FilePath -> String -> IO () appendFile f txt = withFile f AppendMode (\hdl -> hPutStr hdl txt) writeFile :: FilePath -> String -> IO () writeFile f txt = withFile f WriteMode (\hdl -> hPutStr hdl txt)
В самом начале главы я сказал о том, что из мира IO
нет выхода. Нет функции с типом IO a -> a. На самом деле выход есть. Функция с таким типом живёт в модуле System.IO.Unsafe:
unsafePerformIO :: IO a -> a
Длинное имя функции намекает на то, что её необходимо использовать с крайней осторожностью. Поскольку последствия могут быть непредсказуемыми.
Эта функция используется при чтении конфигурационных файлов. Если есть уверенность в том, что файл будет только читаться и во время выполнения программы файл не может быть изменён другой программой, то мы можем считать, что его значение окажется неизменным на протяжении работы программы. Это говорит о том, что нам не важно когда читать данные. Поэтому здесь мы вроде бы ничем не рискуем. “Вроде бы” потому что ответственность за постоянство файла лежит на наших плечах.
Эта функция часто используется при вызове функций С через Haskell. В Haskell есть возможность вызывать функции, написанные на C. Но по умолчанию такие функции заворачиваются в тип IO. Если функция является чистой в С, то она будет чистой и при вызове через Haskell. Мы можем поручиться за её чистоту и вычислитель нам поверит. Но если мы его обманули, мы пожнём плоды своего обмана.
Раз уж речь зашла о “грязных” возможностях языка стоит упомянуть функцию trace из модуля Debug.Trace. Посмотрим на её тип:
trace :: String -> a -> a
Это служебная функция эхо-печати. Когда дело доходит до вычисления функции trace на экран выводится строка, которая была передана в неё первым аргументом, после чего функция возвращает второй аргумент. Это функция id с побочным эффектом вывода сообщения на экран. Ею можно пользоваться для отладки. Например так можно вернуть значение и распечатать его:
echo :: Show a => a -> a echo a = trace (show a) a
Эта глава завершает наше путешествие в мире типов-монад. Мы начали наше знакомство с монадами с композиции, мы определили класс Monad через класс Kleisli, который упрощал составление специальных функций вида a -> m b. Тогда мы познакомились с самыми простыми типами монадами (списки и частично определённые функции), потом мы перешли к типам посложнее, мы научились проводить вычисления с состоянием. В этой главе мы рассмотрели самый важный тип монаду IO. Мне бы хотелось замкнуть этот рассказ на теме композиции. Мы поговорим о композиции нескольких монад.
Если вы посмотрите в исходный код библиотеки transformers, то увидите совсем другое определение для State:
type State s = StateT s Identity
newtype StateT s m a = StateT { runStateT :: s -> m (a,s) }
newtype Identity a = Identity { runIdentity :: a }
Но так ли оно далеко от нашего? Давайте разберёмся. Identity это тривиальный тип обёртка. Мы просто заворачиваем значение в конструктор и ничего с ним не делаем. Вы наверняка сможете догадаться как определить экземпляры всех рассмотренных в этой главе классов для этого типа. Тип StateT больше похож на наше определение для State, единственное отличие – это дополнительный параметр m в который завёрнут результат функции обновления состояния. Если мы сотрём m, то получим наше определение. Это и сказано в определении для State
type State s = StateT s Identity
Мы передаём дополнительным параметром в StateT тип Identity, который как раз ничего и не делает с типом. Так мы получим наше исходное определение, но зачем такие премудрости? Такой тип принято называть монадным трансформером (monad transformer). Он определяет композицию из нескольких монад в данном случае одной из монад является State. Посмотрим на экземпляр класса Monad для StateT
instance (Monad m) => Monad (StateT s m) where
return a = StateT $ \s -> return (s, a)
a >>= f = StateT $ \s0 ->
runStateT a s0 >>= \(b, s1) -> runStateT (f b) s1
В этом определении мы пропускаем состояние через сито методов класса Monad для типа m. В остальном это определение ничем не отличается от нашего. Также определены и ReaderT, WriterT, ListT и MaybeT. Ключевым классом для всех этих типов является класс MonadTrans:
class MonadTrans t where
lift :: Monad m => m a -> t m a
Этот тип позволяет нам заворачивать специальные значения типа m в значения типа t. Посмотрим на определение для StateT:
instance MonadTrans (StateT s) where
lift m = StateT $ \s -> liftM (,s) m
Напомню, что функция liftM это тоже самое , что и функция fmap, только она определена через методы класса Monad. Мы создали функцию обновлнения состояния, которая ничего не делает с состоянием, а лишь прицепляет его к значению.
Приведём простой пример применения трансформеров. Вернёмся к примеру FSM из предыдущей главы. Предположим, что наш конечный автомат не только реагирует на действия, но и ведёт журнал, в который записываются все поступающие на вход события. За переход состояний будет по прежнему отвечать тип State только теперь он станет трансформером, для того чтобы включить возможность журналирования. За ведение журнала будет отвечать тип Writer. Ведь мы просто накапливаем записи.
Интересно, что для добавления новой возможности нам нужно изменить лишь определение типа FSM и функцию fsm, теперь они примут вид:
module FSMt where
import Control.Monad.Trans.Class
import Control.Monad.Trans.State
import Control.Monad.Trans.Writer
import Data.Monoid
type FSM s = StateT s (Writer [String]) s
fsm :: Show ev => (ev -> s -> s) -> (ev -> FSM s)
fsm transition e = log e >> run e
where run e = StateT $ \s -> return (s, transition e s)
log e = lift $ tell [show e]
Все остальные функции останутся прежними. Сначала мы подключили все необходимые модули из библиотеки transformers. В подфункции log мы сохраняем сообщение в журнал, а в подфункции run мы выполняем функцию перехода. Посмотрим, что у нас получилось:
*FSMt> let res = mapM speaker session *FSMt> runWriter $ runStateT res (Sleep, Level 2) (([(Sleep,Level 2),(Work,Level 2),(Work,Level 3),(Work,Level 2), (Sleep,Level 2)],(Sleep,Level 3)), ["Button","Louder","Quieter","Button","Louder"]) *FSMt> session [Button,Louder,Quieter,Button,Louder]
Мы видим, что цепочка событий была успешно записана в журнал.
Для трансформеров с типом IO определён специальный класс:
class Monad m => MonadIO m where
liftIO :: IO a -> m a
Этот класс живёт в модуле Control.Monad.IO.Class. С его помощью мы можем выполнять IO-действия внутри другой монады. Эта возможность бывает очень полезной. Вам она обязательно понадобится, если вы начнёте писать веб-сайты на Haskell (например в happstack) или будете пользоваться библиотеками, которые надстроены над C (например физический движок Hipmunk).
Наконец-то мы научились писать программы! Программы, которые можно исполнять за пределами интерпретатора. Для этого нам пришлось познакомиться с типом IO. Экземпляр класса Monad для этого типа интерпретируется специальным образом. Он вносит упорядоченность в выполнение программы. В нашем статическом мире описаний появляются такие понятия как “сначала”, “затем”, “до” и “после”. Но они не смогут нанести много вреда.
Вычисление операций с побочными эффектами разбивает программу на кадры. Но это не мешает нам писать основные функции в чистом виде, подставляя их по мере необходимости в изменчивый мир побочных эффектов с помощью методов из классов Functor, Applicative, Monad.
Мы узнали как в Haskell обстоят дела с такими типичными задачами мира побочных эффектов как ввод/вывод, чтение/запись файлов, генерация случайных значений, выполнение внешних программ, инициализация программ с помощью флагов. Также мы узнали о том, как обрабатываются специфические для типа IO исключения.
Старайтесь свести присутствие функций с побочными эффектами к минимуму. Идеальный случай, когда тип IO встречается только в функции main. Часто программы устроены более хитрым образом и функции с побочными эффектами пытаются расползтись по всему коду. Но даже в этом случае программу можно разделить на две части: в одной живут подлинные источники побочных эффектов, такие как чтение файлов, генерация случайных значений, а в другой – чистые функции. Старайтесь устроить программу так, чтобы она была максимально чистой. Чистые функции гораздо проще комбинировать, понимать, изменять.
Это упражнение даёт вам возможность почувствовать преимущества чистого кода. Вспомните функцию поиска корней методом неподвижной точки (этот пример встречался в главе о ленивых вычислениях). Напишите на основе этого примера программу, которая будет распечатывать решение и последовательность приближений. Последовательность приближений состоит из текущего значения корня и расстоянии между корнями.
Напишите два варианта программы, в одном вы измените алгоритм так, чтобы печать происходила одновременно с вычислениями (не пользуясь функцией из модуля Debug.Trace). А в другом варианте алгоритм останется прежним. Но теперь вместо решения найдите список первых приближений до решения. А затем передайте его в отдельную функцию печати результатов.
В первом варианте алгоритм смешан с печатью. А во втором программа распадается на две части, часть вычислений и часть вывода результатов на экран. Сравните два подхода.
Напишите программу для угадывания чисел. Компьютер загадал число в заданном диапазоне и просит вас угадать его. Если вы ошибаетесь он подсказывает: “холодно-горячо” или “больше-меньше”. Программа принимает два аргумента, которые определяют диапазон возможных значений для неизвестного числа.
С помощью стандартных функций для генерации случайных чисел напишите программу, которая проводит состязание по игре в кости. Программа принимает аргументом суммарное число очков необходимых для победы. Двое игроков бросают по очереди кости побеждает тот, кто первым наберёт заданную сумму.
Сделайте так чтобы результаты выводились постепенно. С каждым нажатием на Enter вы подбрасываете кости (два шестигранных кубика). После каждого раунда программа выводит промежуточные результаты.
Напишите программу, которая принимает два аргумента: набор слов разделённых пробелами и файл. А выводит она строки файла, в которых встречается данное слово.
Воспользуйтесь стандартными функциями из модуля Data.List
-- разбиение строки на подстроки по переносам каретки lines :: String -> [String] -- разбиение строки на подстроки по пробелам words :: String -> [String] -- возвращает True только в том случае, если -- первый список полностью содержится во втором isInfixOf :: Eq a => [a] -> [a] -> Bool
Классы Functor и Applicative замкнуты относительно композиции. Это свойство говорит о том, что композиция (аппликативных) функторов снова является (аппликативным) функтором. Докажите это! Пусть дан тип, который описывает композицию двух типов:
newtype O f g a = O { unO :: f (g a) }
Определите экземпляры классов:
instance (Functor f, Functor g) => Functor (O f g) where ... instance (Applicative f, Applicative g) => Applicative (O f g) where ...
Подсказка: если совсем не получается, ответ можно подсмотреть в библиотеке TypeCompose. Но пока мы не знаем как устанавливать библиотеки и где они живут, всё-таки попытайтесь решить это упражнение самостоятельно.